一、MergeTree系列引擎概述
在ClickHouse中,存储引擎决定了一张表拥有哪些特性以及读写数据的方式等。在所有的存储引擎中,MergeTree及其*MergeTree系列是最强大的表引擎,它适用于一些高负载任务,可以快速插入数据并在后台进行数据处理,还支持了主键索引、分区、数据复制等一些其他引擎不支持的功能。
该类型的引擎包括:
MergeTree
Replacing MergeTree
Summing MergeTree
Aggregating MergeTree
Collapsing MergeTree
Versioned Collapsing MergeTree
Graphite MergeTree
其中,MergeTree引擎具备了这一系列引擎的基本特征,是MergeTree系列引擎的基础,需要注意的是**MergeTree引擎并不属于*MergeTree系列**
二、MergeTree(合并树)引擎
MergeTree插入的数据会直接写入文件系统,故它仅适用于批量插入数据,而不适合频繁插入单行数据的情况,MergeTree在写入一批数据时,数据会以不可修改的数据片段形式写入到磁盘中,同时为了避免数据片段过多,ClickHouse会通过后台线程,定期合并数据片段,属于相同分区的数据片段会被合并为一个新的片段。
1、创建方式
1 | -- MergeTree引擎表的创建格式为 |
2、配置参数介绍
- 必填项:
ENGINE:指定使用的引擎。ORDER BY:排序键,用于指定在一个数据片段内,使用的排序方式。- 当未指定排序键时,默认会使用主键排序,同样的,当未指定主键时,默认会使用排序键作为主键
- 可以是单列名称或多列字段的元组格式。例如:
ORDER BY (CounterId)或``ORDER BY (CounterID, EventDate)` - 当使用多列字段排序,例如
ORDER BY (CounterID, EventDate),在单个数据片段内,会先根据CounterID字段排序,CounterID相同的数据再按照EventDate排序
- 可选项:
PARITION BY:分区键PRIMARY KEY:主键,指定后会按照主键字段生成一级索引,用于加速表查询。默认情况下与ORDER BY子句相同,否则的话主键表达式必须为排序表达式元组的前缀。主键声明后,单个数据片段内会按照主键字段升序排序。MergeTree主键允许数据重复。SAMPLE BY:抽样表达式。若指定了该选项,则主键也必须包含它。例如:...ENGINE = MergeTree() ORDER BY (CounterID, EventDate, intHash32(UserID)) SAMPLE BY intHash32(UserID)TTL:数据生存期,用于指定数据的存储时间。- 表达式中必须包含一个
Date或DateTime类型的列,例如:TTL date + INTERVAL 1 DAY,默认当表中数据达到这个时间时,会删除对应的数据信息 - 也可对满足该表达式的数据进行对应操作,例如:
TTL date + INTERVAL 1 MONTH DELETE|TO DISK 'xxx',对满足表达式的数据,表中删除过期的行并移动到指定的磁盘上 - 可以指定多个规则的操作,但只能有一个
DELETE操作
- 表达式中必须包含一个
SETTING:控制MergeTree的其他可选参数index_granularity:索引粒度,默认值为8192。表示在默认情况下,clickhouse每间隔8192条数据生成一条索引index_granularity_bytes:索引粒度,早期版本只允许index_granularity参数按照间隔数据条数设置索引粒度,后续版本支持该参数设置数据量大小限制索引粒度,默认值为10M,设置为0表示不启动根据数据量自适应功能enable_mixed_granularity_parts:表示是否开启自适应限制索引粒度的功能,默认开启merge_with_ttl_timeout:TTL合并频率的最小时间间隔,默认值为86400(1天)use_minimalistic_part_header_in_zookeeper:设置数据片段头部在zookeeper中的存储方式min_merge_bytes_to_use_direct_io:当数据量大于这个值时,使用直接I/O来读取数据并进行合并操作,默认值为10G,设置为0时表示禁用直接I/Ostorage_policy:设置存储策略
三、MergeTree存储结构
1 | -- 创建测试数据库 |
执行上述操作后,查看clickhouse中test库下的数据目录如下:
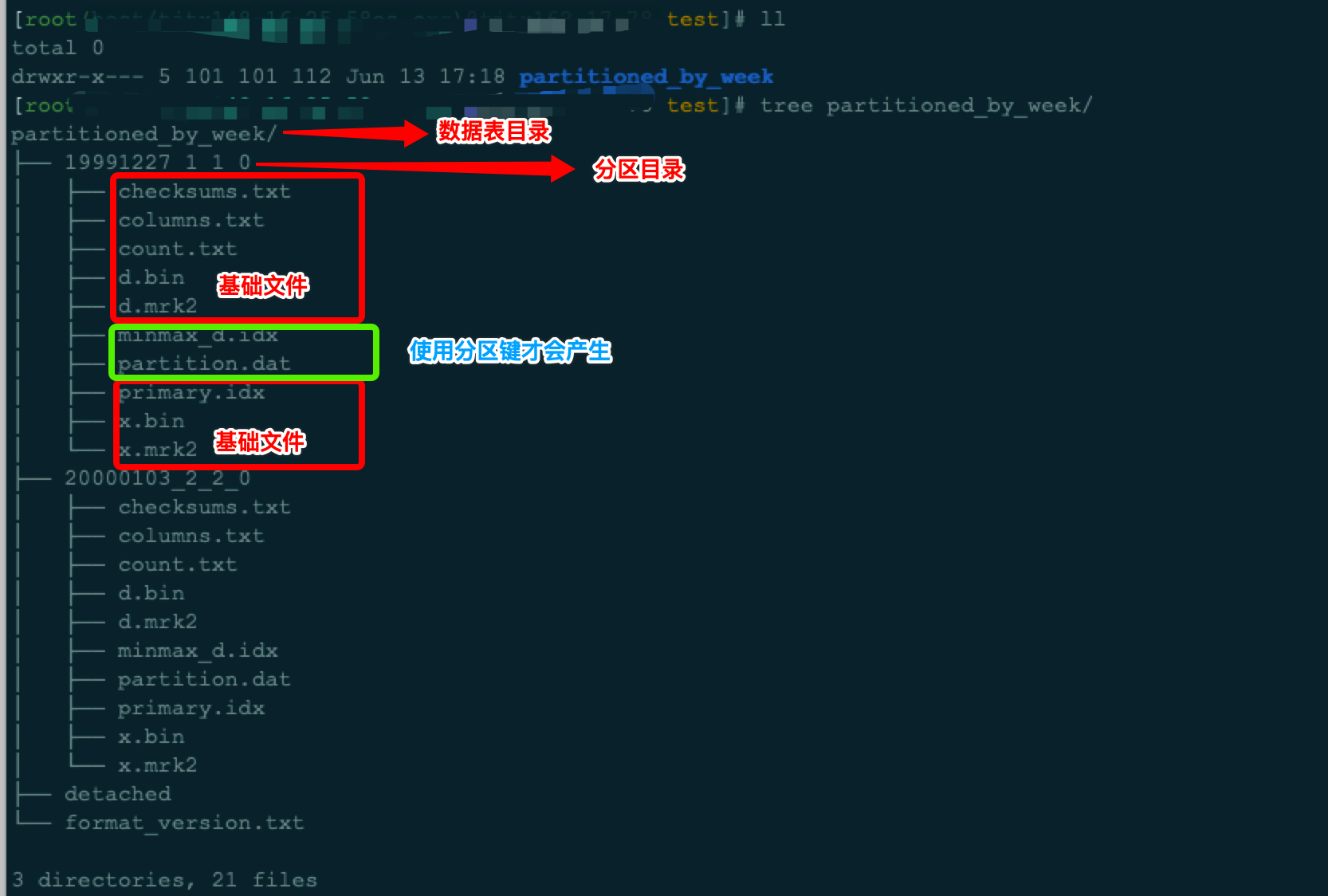
可以看出,一张表完整的物理结构由表目录、分区目录、数据文件作为层级组成,他们各自的作用如下:
partition:分区目录
- 测试数据中分区目录为
19991227_1_1_0和20000103_2_2_0,属于相同分区的数据,会被合并到同一个分区目录中
- 测试数据中分区目录为
checksums.txt:校验文件
- 按二进制格式存储,保存了剩余数据文件的大小及其哈希值,用于快速校验数据文件的完整性和准确性
columns.txt:列信息文件
- 使用明文存储,用于保存该分区目录下的列字段信息。例如:
1
2
3
4
5[root@xxxx test]# cat partitioned_by_week/19991227_1_1_0/columns.txt
columns format version: 1
2 columns:
`d` Date
`x` UInt8count.txt:计数文件
- 使用明文存储,记录保存了当前数据分区目录下的数据行数。例如:
1
2[root@xxxx test]# cat partitioned_by_week/19991227_1_1_0/count.txt
2primary.idx:一级索引文件
- 使用二进制格式存储。用于存放稀疏索引,一张MergeTree通过ORDER BY或PRIMARY KEY只能声明一个一级索引
[column].bin:数据文件
- 默认使用LZ4压缩格式存储。用来存放该数据分区的某列的数据。MergeTree采用了列式存储,故每列字段都有独立的bin数据文件,以列名命名。
[column].mrk或[column].mrk2:列字段标记文件
- 使用二进制格式存储。保存了[column].bin文件的偏移量信息,MergeTree通过该文件建立了primary.idx稀疏索引与[column].bin文件之间的映射关系。它会先通过primary.idx找到对应数据的偏移量信息column.mrk,再通过偏移量直接从[column].bin文件中读取数据。该文件与[column].bin文件一一对应,也是每列字段都有独立的mrk文件,如果使用了自适应大小的索引间隔,会以.mrk2命名
partition.dat和minmax_d.idx:分区索引文件
- 当使用了分区键,例如
PARTITION BY toMonday(d),便会生成partition.dat和minmax_d.idx索引文件,均适用二进制格式存储。 - partition.dat用于保存当前分区下,分区表达式最终生成的值
- minmax_d.idx用于记录当前分区下,分区字段对应原始数据的最小和最大值
- 当使用了分区键,例如