一、按列存储
在MergeTree中,数据按列存储,每个字段也独立单独存储,每个列字段均拥有一个对应的column.bin数据文件,这些数据文件便为数据的物理存储。数据文件以分区目录的形式被组织存放,所以每个分区目录中的bin文件只保存了当前分区片段内的该列数据。按列独立存储有利于更好的进行数据压缩(相同类型数据存放在一起),还可以最小化需扫描数据的范围。
MergeTree会将经过压缩的数据存放到对应column.bin文件中,默认使用LZ4算法,然后将数据按照声明的ORDER BY排序。最后,数据会以压缩数据块的方式被有序的写入数据文件中的。
二、压缩数据块
1、简介
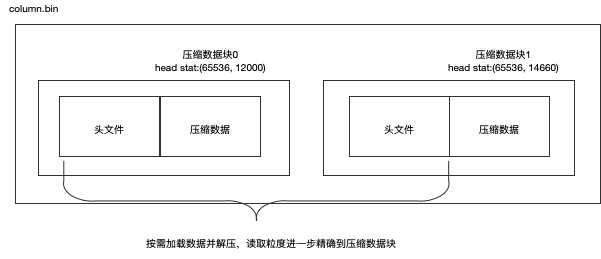
一个压缩数据块由头信息和压缩数据两部分组成。头信息固定使用9位字节表示,具体由1个UInt8(1字节)和2个UInt32(4字节)整型组成,分别代表了使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小,具体格式如图所示:

从上图可以看出,column.bin文件由多个压缩数据块组成,每个压缩数据块的头部信息是基于CompressionMethod_CompressedSize_UncompressedSize公式生成,可通过ClickHouse提供的clickhouse-compressor工具查询到某个.bin文件中压缩数据的统计信息。这里以官方提供的测试数据hit_v1为例,执行该命令:
1 | clickhouse-compressor --stat < /var/lib/clickhouse/data/datasets/hits_v1/201403_1_32_2/JavaEnable.bin |
每个压缩数据块的体积,按照其压缩前的数据字节大小,被严格控制在64KB~1MB之间,上下限大小由min_compress_block_size(默认65536)和max_compress_block_size(默认1048576)参数指定。而每一个压缩数据块最终大小,则和一个index_granularity内实际的数据大小有关。
1 | clickhouse-server_1 :) select * from system.settings where name like '%_compress_block_size%'\G |
2、压缩规则及流程
MergeTree在数据存储过程中,会遵循以下规则:
- 单个索引粒度间隔数据size < 64KB:如果单个索引粒度数据大小小于64KB,则继续获取下一个索引粒度的数据,一直到size >= 64KB,生成下一个压缩数据块。
- 单个索引粒度间隔数据 64KB <= size <= 1MB:如果单个索引粒度数据大小大于64KB,小于1MB,则直接生成下一个压缩数据块
- 单个索引粒度间隔数据 size > 1MB:如果单个索引粒度数据大小超过1MB,则先按照1MB大小截断并生成下一个压缩数据块,剩余数据按照这三个规则对应执行。这时就会出现一批数据生成多个压缩数据块的情况。

3、总结
一个column.bin文件是由一个到多个压缩数据块组成的,每个压缩数据块大小在64KB~1MB之间。多个压缩数据块之间,按照写入顺序首尾相接,紧密排列在一起。数据被压缩后可以减少数据大小,降低存储空间并且加快数据的传输效率,但数据的压缩和解压动作,本身也会带来额外的性能损耗,所以需要控制被压缩数据的大小。另外,在具体读取某一列的压缩数据时,首先需要将压缩数据(包含了整个压缩数据块以及下个压缩数据块的头文件)加载到内存并解压,再进行后续的数据处理。通过压缩数据块,可以在不读取整个.bin文件的情况下将读取粒度降低到压缩数据块级别,进一步缩小了数据读取的范围。