一、研究背景
在利用python库multiprocessing进行多进程开发时,利用了进程池及apply_async异步非阻塞进行函数调用时,为了代码逻辑清晰以及代码块功能最小化,下一步的调用使用到了第一次apply_async的结果,将两个异步调用执行变成了同步执行,导致异步1min可以执行完成的程序变成了10min才执行完成,将优点变成了缺点。
这里将对源代码进行分析,并进行修改。
原本代码类似如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| from multiprocessing import Pool
def getA(info):
info['test1'] = 'test1'
info['test2'] = 'test2'
return info
def getB(info):
a = {}
a['test'] = info['test1'] + '_' + info['test2']
print(a)
return a
if __name__ == '__main__':
try:
msg = 'success'
pool = Pool(4)
infoList = [{'a': 'a1', 'b': 'b1'}, {'a': 'a2', 'b': 'b2'}]
for info in infoList:
basicinfo = pool.apply_async(getA, (info, ))
baseinfo = basicinfo.get()
pool.apply_async(getB, (baseinfo, ))
pool.close()
pool.join()
print(msg)
except Exception as err:
print(err)
|
执行结果:
1
2
3
| {'test': 'test1_test2'}
{'test': 'test1_test2'}
success
|
二、原因分析
apply_async属于异步非阻塞模式,原本的代码使用了两次pool.apply_async(),并且第二次的apply_async需要利用第一次apply_async的结果,这就表示本来应该是两次异步同一时间执行两个函数,现在第二个函数需要等待第一个函数执行完之后再执行,产生了等待时间,从而将程序执行时长扩大。以下通过上述getA和getB示例详细描述原因:
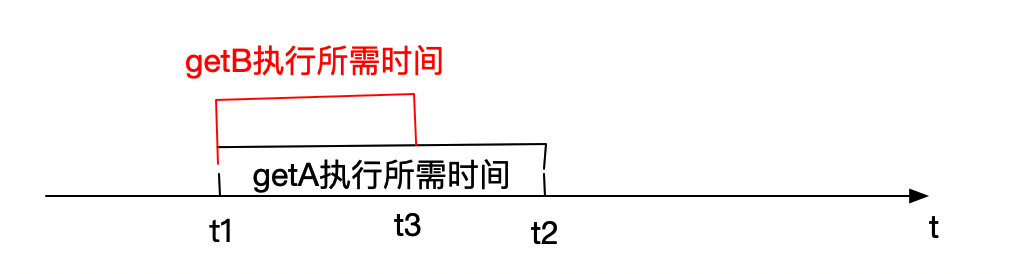
上图为apply_async方法适合用的场景,该场景两个调用函数并不关心对方的结果,getA与getB函数可以同时执行,到了t2时刻执行时间最长的getA函数执行结束,则该程序执行结束。
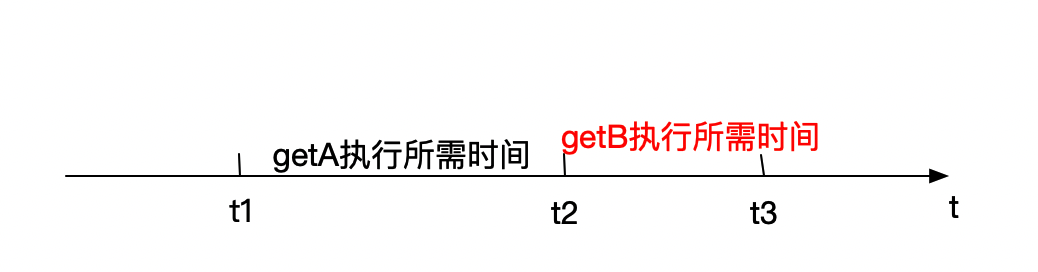
而本次的需求实际为上图所示,虽然都使用了apply_async的异步模式,但getB函数需接收getA执行完成的结果,导致getB函数并没有和getA同时开始执行,getB从t1时刻就开始等待getA的执行结果,直到t2时刻getA执行完成返回结果之后,getB才开始执行,直到t3时刻执行结束。
三、处理方法
1、合并调用函数
该方法是将底层的getA和getB两个函数,合并为一个函数getC执行,之后使用一次apply_async执行即可。修改代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| from multiprocessing import Pool
def getA(info):
info['test1'] = 'test1'
info['test2'] = 'test2'
return info
def getB(info):
a = {}
a['test'] = info['test1'] + '_' + info['test2']
return a
def getC(info):
info_a = getA(info)
info_b = getB(info_a)
print(info_b)
return info_b
if __name__ == '__main__':
try:
msg = 'success'
pool = Pool(4)
infoList = [{'a': 'a1', 'b': 'b1'}, {'a': 'a2', 'b': 'b2'}]
for info in infoList:
basicinfo = pool.apply_async(getC, (info, ))
pool.close()
pool.join()
print(msg)
except Exception as err:
print(err)
|
执行结果:
1
2
3
| {'test': 'test1_test2'}
{'test': 'test1_test2'}
success
|
2、使用回调函数
另外一种方式是使用apply_async所包含的回调函数,回调函数的格式为apply_async(func1, args=(input, ), callback=func2),意思就是将func1函数的返回传递给func2,并且由主进程继续执行func2函数,修改代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| from multiprocessing import Pool
import os
def getA(info):
info['test1'] = 'test1'
info['test2'] = 'test2'
print('getA pid', os.getpid())
return info
def getB(info):
a = {}
a['test'] = info['test1'] + '_' + info['test2']
print(a)
print('getB pid', os.getpid())
return a
if __name__ == '__main__':
try:
print("主进程pid:", os.getpid())
msg = 'success'
pool = Pool(4)
infoList = [{'a': 'a1', 'b': 'b1'}, {'a': 'a2', 'b': 'b2'}]
for info in infoList:
basicinfo = pool.apply_async(getA, args=(info, ), callback=getB)
pool.close()
pool.join()
print(msg)
except Exception as err:
print(err)
|
执行结果:
1
2
3
4
5
6
7
8
9
10
| 主进程pid: 20006
getA pid 20007
getA pid 20008
{'test': 'test1_test2'}
getB pid 20006
{'test': 'test1_test2'}
getB pid 20006
success
|