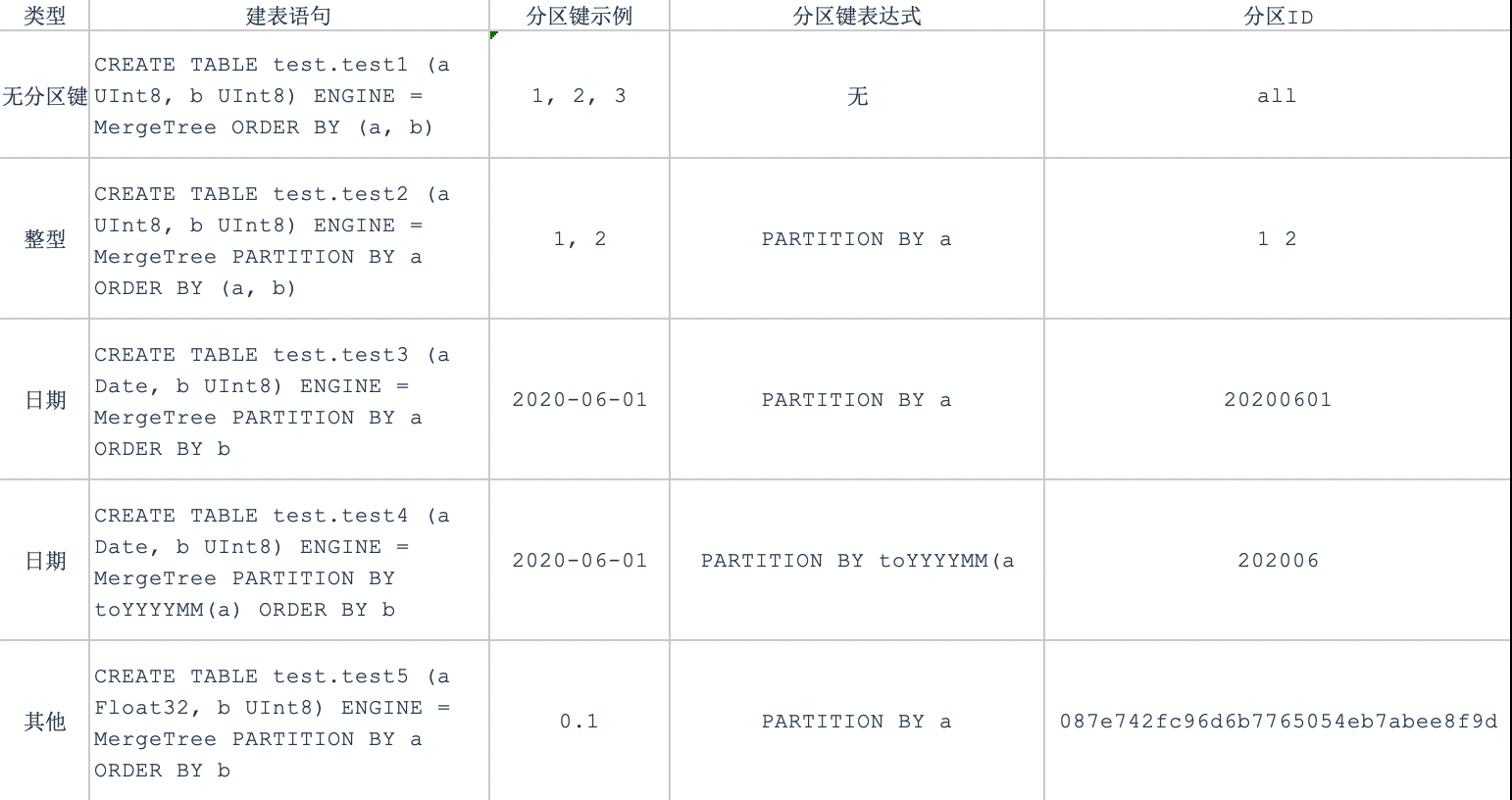
从ClickHouse存储引擎之MergeTree引擎——概述中可以知道,在MergeTree存储引擎中,数据是以分区目录的形式存放的。基于该原理,在进行数据查询时,可以仅查询最小的分区目录。
一、MergeTree数据分区规则
1、测试示例
下面仍然使用上一篇的测试数据来继续说明MergeTree的数据分区方式和规则
- 原始数据情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
[root@xxxx partitioned_by_week]
total 4
drwxr-x--- 2 101 101 221 Jun 13 17:18 19991227_1_1_0
drwxr-x--- 2 101 101 221 Jun 13 17:18 20000103_2_2_0
drwxr-x--- 2 101 101 10 Jun 13 17:15 detached
-rw-r----- 1 101 101 1 Jun 13 17:15 format_version.txt
clickhouse-server_1 :) select * from partitioned_by_week;
SELECT *
FROM partitioned_by_week
┌──────────d─┬─x─┐
│ 2000-01-03 │ 3 │
└────────────┴───┘
┌──────────d─┬─x─┐
│ 2000-01-01 │ 1 │
│ 2000-01-02 │ 2 │
└────────────┴───┘
3 rows in set. Elapsed: 0.004 sec.
clickhouse-server_1 :) show create table partitioned_by_week;
SHOW CREATE TABLE partitioned_by_week
┌─statement────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE test.partitioned_by_week (`d` Date, `x` UInt8) ENGINE = MergeTree PARTITION BY toMonday(d) ORDER BY x SETTINGS index_granularity = 8192 │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.003 sec.
|
- 插入一条新的数据
1
2
3
4
5
6
7
8
|
clickhouse-server_1 :) insert into partitioned_by_week (d, x) values('2000-01-05', 4)
INSERT INTO partitioned_by_week (d, x) VALUES
Ok.
1 rows in set. Elapsed: 0.004 sec.
|
- 数据内容及数据目录如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
clickhouse-server_1 :) select * from partitioned_by_week
SELECT *
FROM partitioned_by_week
┌──────────d─┬─x─┐
│ 2000-01-03 │ 3 │
└────────────┴───┘
┌──────────d─┬─x─┐
│ 2000-01-01 │ 1 │
│ 2000-01-02 │ 2 │
└────────────┴───┘
┌──────────d─┬─x─┐
│ 2000-01-05 │ 4 │
└────────────┴───┘
4 rows in set. Elapsed: 0.009 sec.
clickhouse-server_1 :) SELECT partition,name,active FROM system.parts WHERE table = 'partitioned_by_week'
SELECT
partition,
name,
active
FROM system.parts
WHERE table = 'partitioned_by_week'
┌─partition──┬─name───────────┬─active─┐
│ 1999-12-27 │ 19991227_1_1_0 │ 1 │
│ 2000-01-03 │ 20000103_2_2_0 │ 1 │
│ 2000-01-03 │ 20000103_3_3_0 │ 1 │
└────────────┴────────────────┴────────┘
3 rows in set. Elapsed: 0.012 sec.
[root(host/tjtx148-16-25.58os.org)@tjtx162-17-78 partitioned_by_week]
total 4
drwxr-x--- 2 101 101 221 Jun 13 17:18 19991227_1_1_0
drwxr-x--- 2 101 101 221 Jun 13 17:18 20000103_2_2_0
drwxr-x--- 2 101 101 221 Jun 27 10:20 20000103_3_3_0
drwxr-x--- 2 101 101 10 Jun 13 17:15 detached
-rw-r----- 1 101 101 1 Jun 13 17:15 format_version.txt
|
- 查询并查看执行计划
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
clickhouse-server_1 :) select x from partitioned_by_week where d = '2000-01-05'
SELECT x
FROM partitioned_by_week
WHERE d = '2000-01-05'
┌─x─┐
│ 4 │
└───┘
1 rows in set. Elapsed: 0.002 sec.
2020.06.27 10:29:58.383307 [ 81 ] {f0a4f689-76f3-4342-ab8f-2e8349ca5970} <Debug> executeQuery: (from 127.0.0.1:58492) SELECT x FROM partitioned_by_week WHERE d = '2000-01-05'
2020.06.27 10:29:58.383577 [ 81 ] {f0a4f689-76f3-4342-ab8f-2e8349ca5970} <Debug> InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "d = '2000-01-05'" moved to PREWHERE
2020.06.27 10:29:58.383734 [ 81 ] {f0a4f689-76f3-4342-ab8f-2e8349ca5970} <Trace> AccessRightsContext (default): Access granted: SELECT(d, x) ON test.partitioned_by_week
2020.06.27 10:29:58.383836 [ 81 ] {f0a4f689-76f3-4342-ab8f-2e8349ca5970} <Debug> test.partitioned_by_week (SelectExecutor): Key condition: unknown
2020.06.27 10:29:58.383859 [ 81 ] {f0a4f689-76f3-4342-ab8f-2e8349ca5970} <Debug> test.partitioned_by_week (SelectExecutor): MinMax index condition: (column 0 in [10961, 10961])
2020.06.27 10:29:58.383878 [ 81 ] {f0a4f689-76f3-4342-ab8f-2e8349ca5970} <Debug> test.partitioned_by_week (SelectExecutor): Selected 1 parts by date, 1 parts by key, 1 marks to read from 1 ranges
2020.06.27 10:29:58.383924 [ 81 ] {f0a4f689-76f3-4342-ab8f-2e8349ca5970} <Trace> test.partitioned_by_week (SelectExecutor): Reading approx. 8192 rows with 1 streams
2020.06.27 10:29:58.383968 [ 81 ] {f0a4f689-76f3-4342-ab8f-2e8349ca5970} <Trace> InterpreterSelectQuery: FetchColumns -> Complete
2020.06.27 10:29:58.384464 [ 81 ] {f0a4f689-76f3-4342-ab8f-2e8349ca5970} <Information> executeQuery: Read 1 rows, 3.00 B in 0.001 sec., 915 rows/sec., 2.68 KiB/sec.
2020.06.27 10:29:58.384501 [ 81 ] {f0a4f689-76f3-4342-ab8f-2e8349ca5970} <Debug> MemoryTracker: Peak memory usage (for query): 0.00 B.
2020.06.27 10:29:58.384574 [ 81 ] {} <Debug> MemoryTracker: Peak memory usage (total): 0.00 B.
2020.06.27 10:29:58.384595 [ 81 ] {} <Information> TCPHandler: Processed in 0.002 sec.
|
2、MergeTree数据分区规则
从插入数据过程中,数据分区目录的变化可以看出,MergeTree的分区目录不是在表创建的时候就存在的,而是在写入数据的过程中被创建出来,也就是说如果仅创建了表结构,没有任何数据的时候,是不会有分区目录存在的。
各部分的含义及命名规则如下:
MinBlockNum和MaxBlockNum:BlockNum是一个整型的自增长型编号,该编号在单张MergeTree表中从1开始全局累加,当有新的分区目录创建后,该值就加1,对新的分区目录来讲,MinBlockNum和MaxBlockNum取值相同。例如上面示例数据为19991227_1_1_0和20000103_2_2_0,但当分区目录进行合并后,取值规则会发生变化
Level:表示合并的层级。相当于某个分区被合并的次数,它不是以表全局累加,而是以分区为单位,初始创建的分区,初始值为0,相同分区ID发生合并动作时,在相应分区内累计加1
二、MergeTree数据分区合并规则
示例数据以周为分区,可以看出2000-01-02, 2和2000-01-03, 3两条数据最终产生了两个相同分区ID的数据目录20000103_2_2_0和20000103_3_3_0,由于它们是通过两条不同的sql插入进去的数据,所以,在ClickHouse中,即使数据属于相同分区,不同批次写入的数据,MergeTree都会生成不同的分区目录,对于同一个分区而言,会存在多个分区目录的情况。
MergeTree可以通过分区合并将属于相同分区的多个目录合并为一个新的目录(官方描述在10到15分钟内会进行合并<控制该值的参数目前还未找到>,也可直接执行optimize语句),已经存在的就目录在之后某个时刻通过后台任务被删除(默认8分钟之后,暂未找到控制该值的参数)。
1、合并分区后的命名规则
同个分区的数据目录合并后会产生一个新的目录,目录中的索引和数据文件也会进行合并,新目录的命名规则如下:
- PartitionID:分区ID保持不变
- MinBlockNum:取同一个分区内所有目录中最小的MinBlockNum值
- MaxBlockNUm:取同一个分区内所有目录中最大的MaxBlockNum值
- Level:取同一个分区内最大Level值并加1
2、示例
按照示例的两个数据目录以及合并的命名规则,可以得到新的数据目录中PartitionID仍然为20000103,MinBlockNum取两个目录中该值的最小值为2,MaxBlockNum取该值的最大值为3,Level原目录都为0加1等于1,故合并后的目录名称为20000103_2_3_1。

再次插入一个20000103分区的数据进行合并后的目录名称会为20000103_2_4_2,过程如下:
- 插入数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
clickhouse-server_1 :) insert into partitioned_by_week(d, x) values('2000-01-04', 4)
INSERT INTO partitioned_by_week (d, x) VALUES
Ok.
1 rows in set. Elapsed: 0.002 sec.
clickhouse-server_1 :) select * from partitioned_by_week
SELECT *
FROM partitioned_by_week
┌──────────d─┬─x─┐
│ 2000-01-03 │ 3 │
│ 2000-01-05 │ 4 │
└────────────┴───┘
┌──────────d─┬─x─┐
│ 2000-01-01 │ 1 │
│ 2000-01-02 │ 2 │
└────────────┴───┘
┌──────────d─┬─x─┐
│ 2000-01-04 │ 4 │
└────────────┴───┘
5 rows in set. Elapsed: 0.002 sec.
|
- 产生新的数据目录
1
2
3
4
5
6
7
| [root@xxxx test]
total 4
drwxr-x--- 2 101 101 221 Jun 13 17:18 19991227_1_1_0
drwxr-x--- 2 101 101 221 Jun 27 11:26 20000103_2_3_1
drwxr-x--- 2 101 101 221 Jun 27 12:12 20000103_4_4_0
drwxr-x--- 2 101 101 10 Jun 13 17:15 detached
-rw-r----- 1 101 101 1 Jun 13 17:15 format_version.txt
|
- 进行合并
1
2
3
4
5
6
7
| clickhouse-server_1 :) optimize table partitioned_by_week
OPTIMIZE TABLE partitioned_by_week
Ok.
0 rows in set. Elapsed: 0.002 sec.
|
- 合并后数据目录发生变化
1
2
3
4
5
6
7
8
9
|
[root@xxxx test]
total 4
drwxr-x--- 2 101 101 221 Jun 13 17:18 19991227_1_1_0
drwxr-x--- 2 101 101 221 Jun 27 11:26 20000103_2_3_1
drwxr-x--- 2 101 101 221 Jun 27 12:14 20000103_2_4_2
drwxr-x--- 2 101 101 221 Jun 27 12:12 20000103_4_4_0
drwxr-x--- 2 101 101 10 Jun 13 17:15 detached
-rw-r----- 1 101 101 1 Jun 13 17:15 format_version.txt
|
可以看到,分区目录发生合并之后,旧分区目录不会被立即删除,此时旧分区目录在system.parts分区详情表中状态会处于未激活状态(active=0),故查询数据时,这部分分区的数据会被自动过滤。