一、数据标记文件的作用
在MergeTree中,保存数据的物理文件包括索引文件primary.idx、column.bin数据文件和column.mrk数据标记文件(若使用了自适应大小的索引间隔,则标记文件会为column.mrk2),这三种文件帮助人们快速找到需要的数据。如果把MergeTree看为一本书,primary.idx一级索引文件类似于书的一级章节目录,column.bin文件中的数据类似书中具体的文字,而数据标记文件则将一级章节目录和具体文字关联起来。
对于数据标记而言,它记录了两个信息:一是一级章节对应的页码信息;二是对应的文字在某一页中的起始位置信息。通过数据标记文件就可以很快的翻到关注内容所在的页,并知道从第几行开始阅读。
二、数据标记的生成规则
数据标记文件、一级索引的对应关系大致如下:

从上图可以看出列数据标记和索引区间是对齐的,都按照index_granularity(默认8192)索引粒度间隔,故通过索引区间的下标编号就可以直接找到对应的数据标记。
数据标记文件也和column.bin文件一一对应,每一个列字段都有一个对应的column.mrk数据标记文件,用于记录数据在column.bin文件中的偏移量信息。一行标记数据用一个元组表示,元组内包含了两个整型数值的偏移量信息:某段数据区间内,对应的column.bin压缩文件中,压缩数据块的起始偏移量;未压缩数据的起始偏移量。对应关系如下表所示:
| 编号 | 压缩文件中的偏移量 | 解压缩块中的偏移量 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 8192 |
| 2 | 0 | 16384 |
| 3 | 0 | 24576 |
| 4 | 0 | 32768 |
| 5 | 0 | 40960 |
| 6 | 0 | 49152 |
| 7 | 0 | 57344 |
| 8 | 12016 | 0 |
| 9 | 12016 | 8192 |
这里使用了之前MergeTree引擎——数据存储中的示例数据,可以看到在示例数据中,第0个压缩块的大小是12000,而在上表中对应的第0个压缩数据块的截止偏移量是12016,在数据存储的文章中我们知道,压缩数据块包含了压缩数据和头信息,并且为了让读取粒度进一步精确到压缩数据块,加载数据还包含了下一个压缩数据块的头文件,一个压缩数据块的头信息固定由9个字节组成,压缩后大小为8字节,所以这里截止偏移量就为8+12000+8=12016.
由表中还可以看出,每一行标记数据都表示了一个片段的数据(默认8192行)在column.bin压缩文件中的读取位置信息。标记数据和一级索引数据不同,它不能常驻于内存中,clickhouse使用了LRU(最近最少使用)缓存策略加快其获取速度。
三、数据标记的工作方式
MergeTree读取数据时,需要通过标记数据的位置信息再找到需要的数据,整个查找过程大致分为读取压缩数据块和读取数据两个步骤
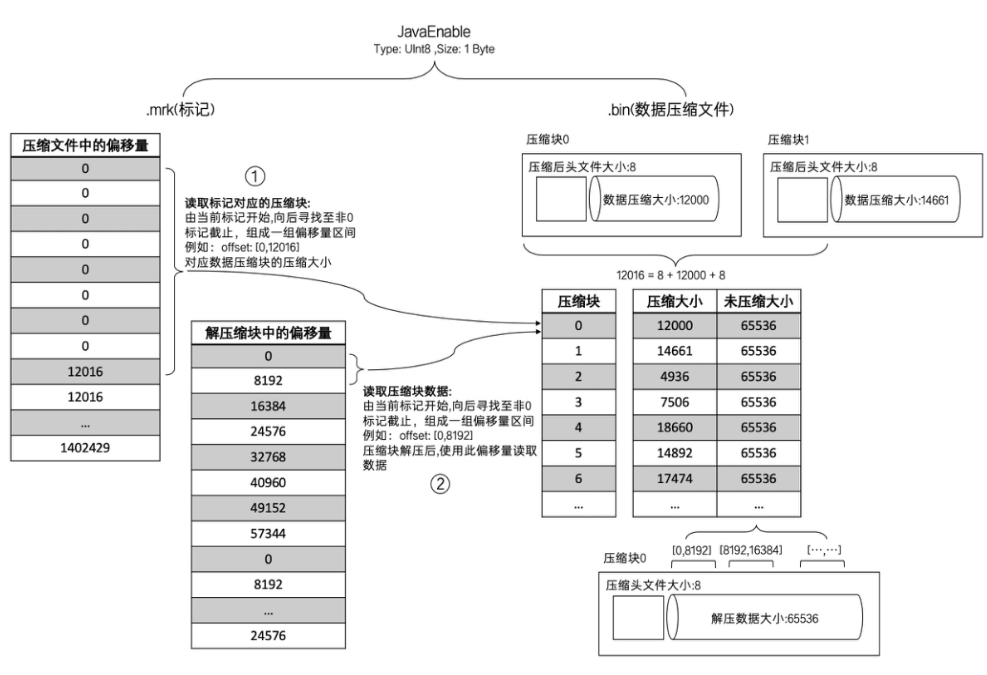
上图为ClickHouse官方提供的hits_v1测试表中,JavaEnable字段标记文件和压缩数据文件的对应关系示例。由于测试表中JavaEnable字段的数据类型为UInt8,该列每行数据大小为1字节,hits_v1表的索引粒度index_granularity为8192,所以一个索引片段的数据大小为8192字节。按照压缩数据块的生成规则,当数据大小在64KB~1MB之间时,生成一个压缩数据块(64K=65536字节,65536/5192=8),所以在该JavaEnable的标记文件中,每8行标记数据对应一个压缩数据块,故从图中可以看到,在标记文件中,压缩文件中8行数据的偏移量相同,这8行标记指向了同一个压缩数据块。由于每一个片段的数据大小都为8192字节,所以解压缩块中每8行的偏移量都按照8192的大小递增,到第9行时,又会置为0,这是由于从这里开始,又生成了下一个压缩数据块。
MergeTree定位压缩数据块并读取数据:
读取压缩数据块
在查询某一列数据时,MergeTree不需要一次性加载所有column.bin文件,而可以根据需要,借助标记文件中保存的压缩数据偏移量只加载特定的数据块。
在上图示例中,上下相邻两个压缩文件的起始偏移量,构成了获取当前标记对应压缩块的偏移量区间。由当前标记数据开始,向下找到不同的压缩文件偏移量为止,此时获得的一组偏移量区间,就是压缩数据块在column.bin数据文件中的偏移量。例如在上图中,读取.bin文件中[0, 12016]字节数据,就能得到第0个压缩数据块的数据。
读取数据
在读取数据时,MergeTree也可以根据需要借助标记文件中保存的解压缩块中的偏移量,以index_granularity的索引粒度加载特定的一小段。标记数据中,上下相邻的两个解压缩块中的偏移起始量,构成了获取当前标记对应数据的偏移量区间。通过这个区间,能在它的压缩块解压之后,按照偏移量按需读取数据。例如,在图中,通过[0, 8192]便能够读取压缩块0中的第一个数据片段。